
数论
数论
模运算
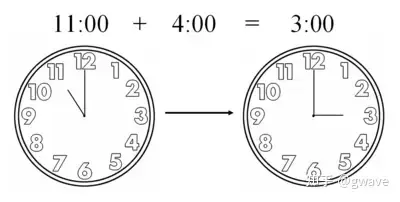
在简单计算可以理解为,a%b = q。q是在a去除以b的余数。但是可以换个角度思考,模运算是为了限制数的范围。例如:我们对一个数据%100,就是将这个数据映射到[1,100)这个范围内。映射到时钟也称时钟算术,与日常生活中的时钟逻辑相似,如:11点后的4个小时是15点,也就是下午3点: 11+4 = 15 ≡ 3 (mod 12)。这里11+4和15 ≡ 3 (mod 12)等价。模运算可以用于周期性问题,本质上是映射处理数据到模数据上。

在对mod构造的一个集合来说,执行一个操作肯定有着对应的逆向操作可以达到同一个结果。这也是之后需要了解的逆元
然后看到知乎的文章,严谨的说法是这样的:


欧几里得算法
公式是这样的:
gcd(a, b) = gcd(b, a mod b)直到b为0
欧几里得的辗转相除法计算的是两个自然数a和b的最大公约数g,意思是能够同时整除a和b的自然数中最大的一个。两个数的最大公约数通常写成gcd(a,b)。要求两个数的最大公约数,不妨假设a>b。假设b是a的约数,那么最大公约数应该是b。所以说最大公约数的上限取决于较小的那个数据,范围为[1,b]。也就是说,我们输入到gcd中的数据一定是一大一小的,这里默认a>b。
特别的如果
gcd(a,b) = 1说明我们的a,b只存在一个公约数1,表明a,b互质
过程是这个样子的,具体看这个文章:
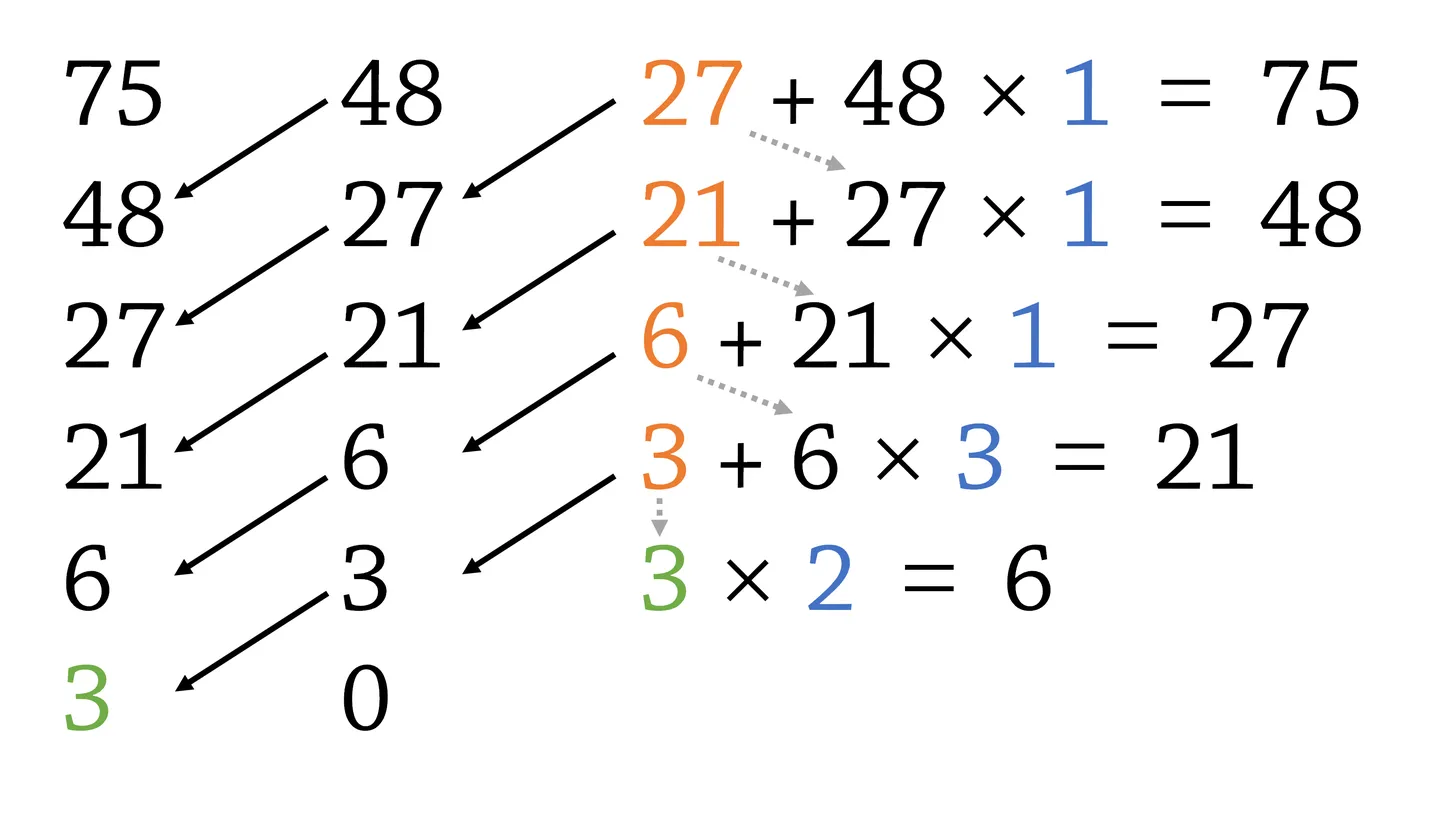
原理是用两者小的数据凑大的数据,余下的数据来凑次小的数据,如此循环?

c++的a/b是向下取整

//两个数据得是整数int open_M(int a,int b){ int result = 1; if(a>b) result = gcd(a,b); else result = gcd(b,a);}
//gcd - 递归计算int gcd(int a,int b){ //简单的记忆 - 只要传入的第二个参数为0 - 那么最大公约数就是第一个参数 if(a%b == 0) return b; else gcd(b,a%b);}用上面的例子可能不好理解,下面用一个图形化实例来解释辗转相除法
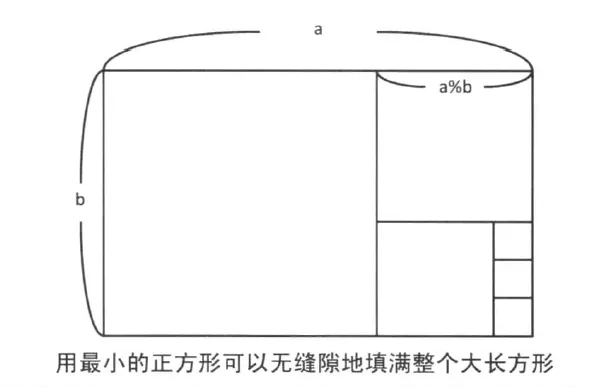
假设我们有一个长方形,其长度为a,宽度为b,我们的目标是找到一个能够完全覆盖这个长方形的最大正方形,而且没有部分超出原始长方形的边界。
首先,我们尝试将较大的长方形(a)分割成较小的长方形(b)和一些余下的部分(q),使得a = b + q,其中q的长度小于b。我们将q看作是原始长方形中未被覆盖的部分。
然后,继续以同样的方式,尝试找到能够完全覆盖q的最大正方形,其长度为b’,同时q = b’ + q’,其中q’的长度小于b’。
我们不断重复这个过程,直到找到一个正方形(b”),它能够完全覆盖q”,其中q” = 0。这时q’‘就是没有一个余下部分的长方形。
这个最终的正方形(b”)的长度就是原始长方形(a)和我们一路上找到的所有正方形(b、b’、…)的最大公约数。
扩展欧几里得
拓展欧几里得就是在迭代过程中,让方程组符合贝祖定律:
设 a, b 为正整数,则关于 x,y 的方程 ax+by=c 有整数解当且仅当是 gcd(a,b) 的倍数。



上面的例子可能讲不太清除,这里举一个浅显的例子:
我们的目的是要计算:
ax+by = gcd(a,b)执行到最终结果b = 0的时候这个式子变为:
ax+0*y = a这样符合这个方程的一个解就是x = 1,y = 0另一种情况,当
b!=0也就是说迭代还在继续,就根据欧几里得算法gcd(a,b) = gcd(b,a%b)这个等式来替换我们迭代过程中的方程。我们要维持ax+by = gcd(a,b)这样的状态,也就是样子上要符合有
gcd(a,b) = ax+by根据gcd(a,b) = gcd(b,a%b)有
gcd(b,a%b) = bx1+(a%b)y1 =
bx1+(a-[a|b]*b)*y1 =
ay1 + b(x1-a/by1)所以说迭代的变量要替换为,
x = y1 , y = x1-a/b*y1. 原因其实就是维持等式不变。

//引用传入int exgcd(int a, int b, int &x, int &y){ if (b == 0) { x = 1; y = 0; return a; } int d = exgcd(b, a % b, x, y), x0, y0; x = y0; y = x0 - (a / b) * y0; return d;}
求解线性同余方程*
形如ax≡b (mod m)这样的方程就是线性同余方程,这个方程的本质上是一个不定方程。将之化为不定方程,结果如下;
由
ax≡b (mod m)得
ax = m(-y)+b既
ax + my = b
一般来说,线性同余方程有无数多种解,但是我们题目一般要求求出整数解就行,由贝祖定理,只要gcd(a,m)|b (只要am的最大公约数可以整除b),那么说明这个方程有整数解。

用拓展欧几里得算法,求解出ax+my = gcd(a,m),由于然后再用求出来的x乘上b/gcd(a,m)
在最后的式子中,我们的m一定是会变成0的
也就是
ax+my = gcd(a,m) 左右两边乘上b/gcd(a,m)就变成了
ax*b/gcd(a,m) + my*b/gcd(a,m) = b这样就可以求出在b条件下的x是多少了,然后再将x带入到原式子,求出y就行。
在扩展欧几里得算法中,我们是通过递归地调用函数来求解贝祖等式:ax + by = gcd(a, b)。当我们调用 exgcd(b, a % b, x1, y1) 时,我们已经知道了 b * x1 + (a % b) * y1 = gcd(b, a % b)。
现在我们希望将这个等式转化为形式 ax + by = gcd(a, b)。为了做到这一点,我们可以使用以下性质:gcd(a, b) = gcd(b, a % b)。通过这个性质,我们可以将 gcd(b, a % b) 替换为 gcd(a, b)。所以,我们得到了 b * x1 + (a % b) * y1 = gcd(a, b)。现在我们的目标是将其转化为 ax + by = gcd(a, b) 的形式。
-
首先,将
(a % b)替换为(a - (a / b) * b),然后整理得到b * x1 + (a - (a / b) * b) * y1 = gcd(a, b)。 -
得到
b * x1 + a * y1 - (a / b) * b * y1 = gcd(a, b)。 -
最后,重新排列得到
a * y1 + b * (x1 - (a / b) * y1) = gcd(a, b)。因此,我们可以令x = y1,y = x1 - (a / b) * y1,从而满足ax + by = gcd(a, b)。(可以理解为样子要符合)
求出x之后需要反代,因为我们求出的是ax+by = gcd(a,b)而不是ax+by = d 只需要判断d是不是d是gcd(a,b)的倍数就可以判断是否是有整数解。
int exgcd(int a,int b,int &x,int &y){ if(b == 0){ x = 1,y = 0; return a; } int x1,y1,d; d = exgcd(b,a%b,x1,y1); x = y1,y = x1-a/b*y1; return d;}
int main(){ int a,b,c,x,y; cin>>a>>b>>c; int d = exgcd(a,b,x,y); if(c%d == 0) cout<<c/d*x<<c/d*y<<" "; else puts("no"); return 0;}快速幂
顾名思义,这个算法实现的是快速求取高幂次的数据。在我们平常计算幂的数据的时候,通常会选择一个一个乘,举个例子:
//例如我要计算 7^10void c(){ int a = 7; for(int i = 1;i<=10;i++){ a*=7; }}这样子确实能够实现我们的目的,但是由于循环次数过多导致算法效率太慢,我们就不使用这种算法,改为使用快速幂算法。
让我们先来思考一个问题:7的10次方,怎样算比较快?
方法1:最朴素的想法,7*7=49,49*7=343,… 一步一步算,共进行了9次乘法。
这样算无疑太慢了,尤其对计算机的CPU而言,每次运算只乘上一个个位数,无疑太屈才了。这时我们想到,也许可以拆分问题。
方法2:先算7的5次方,即7*7*7*7*7,再算它的平方,共进行了5次乘法。
但这并不是最优解,因为对于“7的5次方”,我们仍然可以拆分问题。
方法3:先算7*7得49,则7的5次方为49*49*7,再算它的平方,共进行了4次乘法。
模仿这样的过程,我们得到一个在O(log n)时间内计算出幂的算法,也就是快速幂。
那要怎么样才能实现这种效果呢,我们可以使用二进制来优化我们的乘法运算(其实也是倍增思想),使其更加高效的相乘。

//非递归快速幂int qpow(int a, int n){ int ans = 1; while(n){ if(n&1) //如果n的当前末位为1 ans *= a; //ans乘上当前的a a *= a; //a自乘 - 提高幂,就是和十进制的十位百位一样的 n >>= 1; //n往右移一位,个位数算过了,进位了 } return ans;}最初ans为1,然后我们一位一位算:
1010的最后一位是0,所以a^0这一位不要。然后1010变为101,a进位变为a^1。
101的最后一位是1,所以a^1这一位是需要乘的,乘入ans。101变为10,a再自乘进位a^2。
10的最后一位是0,跳过,右移,自乘进位。
1的最后一位是1,ans再乘上7^8。循环结束,返回结果。

上面所述的都是整数的快速幂,但其实,在算 a^n 时,只要a的数据类型支持乘法且满足结合律,快速幂的算法都是有效的。矩阵、高精度整数,都可以照搬这个思路。下面给出一个模板:
//泛型的非递归快速幂template <typename T>T qpow(T a, ll n){ T ans = 1; // 赋值为乘法单位元,可能要根据构造函数修改 while (n) { if (n & 1) ans = ans * a; // 这里就最好别用 自乘了,不然重载完*还要重载*=,有点麻烦。 n >>= 1; a = a * a; } return ans;}乘法逆元
讨论有关于取模运算的乘法逆元,既对于整数a,与a互质的数b作为模数,当整数x满足ax mod b ≡ 1时,称x为a关于模b的逆元,也就是a * x % b = 1
逆元这个概念是要根据算术法则来定义的,在实数算术中,一个数据的逆元是它的倒数。在mod运算中,我们定义x满足
ax mod b ≡ 1时,称x为a关于模b的逆元
拓展欧几里得实现逆元
在上面我们了解过了,扩展欧几里得算法则是求ax+by = gcd(a,b)的一组可行解:
我们来看它和乘法逆元的关系:
- 逆元:
ax = 1(mod m)可以变形为ax+my = 1 - 拓展欧几里得:求方程
ax+by = gcd(a,b)的一组可行解
也就是要求ax+my = gcd(a,m)中的x,要满足gcd(a,m) = 1就要满足a和m互质,这里可以简化判断条件。处理结果x = (x%m+m)%m(原理是将负数映射到[0,m]中) 这个处理结果保证得到的结果是最小正整数。

//扩展欧几里得算法实现逆元int exgcd(int a, int b, int &x, int &y){ //最终推导式子 if (b == 0) { x = 1; y = 0; return a; } int r = exgcd(b, a % b, x, y); int t = x; x = y; y = t - a / b * y; return r;}
int inverse(int a, int m){ int x, y; int gcd = exgcd(a, m, x, y); return x >= 0 ? x : x + m;//通过取模变为正数}快速幂实现乘法逆元
本质上是使用费马小定理,下面简单介绍一下费马小定理。
费马小定理:对于整数 a 与质数 b ,若 a 与 b 互质,则有:a^(b-1) mod b ≡ 1
拆一下也就变成了a*a^(b-2) mod b ≡ 1 也就将乘法逆元的公式拼凑成功了。然后就是进行幂的运算,这样使用快速幂即可。
求逆元,就用 b-2 和 b 代替 快速幂取模中的 n 和 mod:
时间复杂度:大约O(log b)。适用范围:一般在模数 b 是质数的时候。
#include <iostream>
using namespace std;
// 计算a的幂次b模m的结果long long fm(long long a, long long b, long long m) { long long result = 1; a %= m; while (b > 0) { if (b % 2 == 1) { result = (result * a) % m; } //取模,防止溢出扰乱映射 a = (a * a) % m; b /= 2; } return result;}
// 计算a关于模数m的乘法逆元long long mi(long long a, long long m) { // 使用快速幂计算a^(m-2) % m return fm(a, m - 2, m);}
int main() { long long a, m; cout << "请输入整数a:"; cin >> a; cout << "请输入模数m:"; cin >> m;
long long inverse = mi(a, m);
cout << "整数 " << a << " 关于模数 " << m << " 的乘法逆元是:" << inverse << endl;
return 0;}欧拉函数
任意给定正整数n,请问在小于等于n的正整数之中,有多少个与n构成互质关系?(比如,在1到8之中,有多少个数与8构成互质关系?)
计算这个值的方法就叫做欧拉函数,用φ(n)表示。在1到8之中,与8形成互质关系的是1、3、5、7,所以 φ(n) = 4。
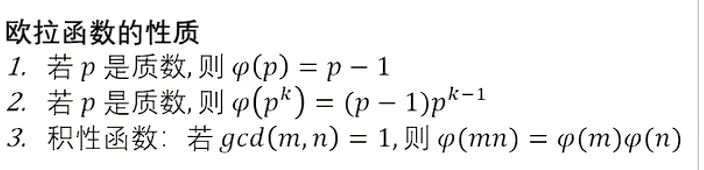
试除法求取欧拉函数,将质数一个一个除掉。

const int N = 1000010;int p[N],vis[N],cnt;int phi[N];//递推每个位置的欧拉函数值
void get_phi(int n){ phi[1] = 1; //枚举每个数据 - 判断质数 for(int i = 2;i<=n;i++){ if(!vis[i]){ p[cnt++] = i; phi[i] = i-1; } } //划掉合数 for(int j = 0;i*p[i]<=n;j++){ phi[m] = p[j]*phi[i]; break; } else //是质数,就加上个数 phi[m] = (p[j]-1)*phi[i];}
对于任何正整数n和与n互质的正整数a(即,a和n没有共同的质因数),以下等式成立:
a^φ(n) ≡ 1 (mod n)其中,^表示幂运算,
φ(n)表示欧拉函数(Euler's Totient Function),≡ 表示模同余。φ(n)表示小于等于n且与n互质的正整数的个数。
//欧拉定理的代码生成#include"iostream"
using namespace std;
//定义欧拉函数long euler(long n){ long ans=n,i,j; for ( i=2;i*i<=n;i++) { if(n%i==0) { ans=ans-ans/i; while(n%i==0) { n/=i; } } } if(n>1) { ans=ans-ans/n; } return ans;}
int main(){ long n;
cout << "请输入一个正整数:"; cin >> n; cout << "此数的欧拉函数值为:"<< euler(n) << endl; return 0;}费马小定理
对于费马小定理,可以理解为是欧拉函数的一种特殊状态,a^φ(n) ≡ 1 (mod n).下面列出的是欧拉函数的公式
a^(p-1) ≡ 1 (mod p)
这里举一个例子:
2^5-1 = 2^4 = 16 ≡ 1(mod 5)
可以看出,mod的这个质数之后会余下1,这个性质朴素存在,但是也有例外:

对于定理的证明,可以观看这个视频,然后下面是实现费马小定理的代码:
#include <iostream>
// 计算 (a^b) % mod,使用费马小定理long long mod_pow(long long a, long long b, long long mod) { if (b == 0) { return 1;
} long long result = 1; a %= mod; while (b > 0) { if (b % 2 == 1) { result = (result * a) % mod; } a = (a * a) % mod; b /= 2; } return result;}
// 计算 a 在模 mod 下的逆元,使用费马小定理long long mod_inverse(long long a, long long mod) { return mod_pow(a, mod - 2, mod);}
int main() { long long a = 7; // 你的底数 long long mod = 13; // 你的模数 long long result = mod_pow(a, mod - 2, mod); std::cout << "逆元: " << result << std::endl; return 0;}费马小定理常用于实现别的算法,实现自己的就很少。
乘法逆元和组合性数学也可以使用这个来实现,了解即可
中国剩余定理
中国剩余定理是为了解决一元线性同余方程组而存在的。

我们可以使用构造法,将方程构造成适合求解逆元的形式:
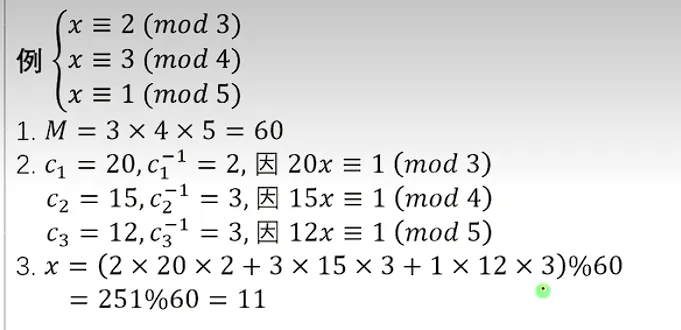
计算步骤如下(但是我不知道怎么证明就是了)
-
首先将所有mod的数相乘,得到一个M
-
然后计算,每一个方程中的
Ci = M/p,这里的p是每一个方程mod的数据。对于每一个C1i,我们求解它的逆元Ci^-1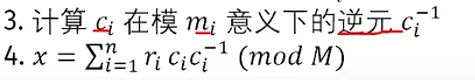

这里的r表示每一个方程的余数,但是这样为啥能够求出来我不太清楚。我们要求逆元,只能用拓展欧几里得算法来实现,下面是模版代码:
#include <iostream>#include <vector>
using namespace std;
// 计算模反元素的函数,使用扩展欧几里得算法long long exgcd(long long a, long long m) { long long m0 = m, x0 = 0, x1 = 1; while (a > 1) { long long q = a / m; m = a % m; a = m0; m0 = m; long long temp = x0 - q * x1; x0 = x1; x1 = temp; } return x1 < 0 ? x1 + m0 : x1;}
// 实现中国剩余定理的函数long long ct(const vector<long long>& a, const vector<long long>& n) { // 确保输入的 a 和 n 有相同的长度 if (a.size() != n.size()) { throw invalid_argument("The input vectors must have the same size."); }
long long N = 1; for (long long ni : n) { N *= ni; }
long long result = 0; for (size_t i = 0; i < a.size(); ++i) { long long Ni = N / n[i]; result += a[i] * Ni * exgcd(Ni, n[i]); }
return result % N;}
int main() { // 例子:解 x ≡ 2 (mod 3), x ≡ 3 (mod 5), x ≡ 2 (mod 7) vector<long long> a = {2, 3, 2}; vector<long long> n = {3, 5, 7};
long long solution = ct(a, n); cout << "The solution is: " << solution << endl;
return 0;}高斯消元
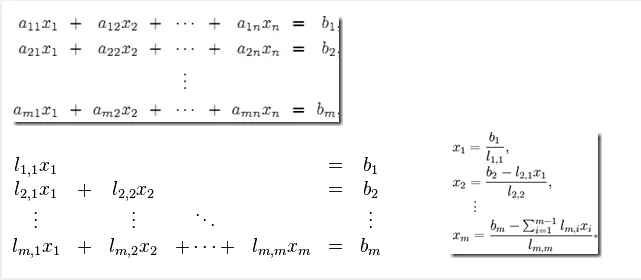
高斯消元法,是线性代数中的一个算法,可用来求解线性方程组,并可以求出矩阵的秩,以及求出可逆方阵的逆矩阵。 高斯消元法的原理是: 若用初等行变换将增广矩阵 化为 ,则AX = B与CX = D是同解方程组。
所以我们可以用初等行变换把增广矩阵转换为行阶梯阵,然后回代求出方程的解。
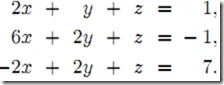
构造增广矩阵,即系数矩阵A增加上常数向量b(A|b)

通过以交换行、某行乘以非负常数和两行相加这三种初等变化将原系统转化为更简单的三角形式(triangular form)
注:这里的初等变化可以通过系数矩阵A乘上初等矩阵E来实现

从而得到简化的三角方阵组,注意它更容易解
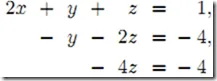
这时可以使用向后替换算法(也就是最后的方程向前带) 求解得 z=-4/-4=1, y=4-2z=4-2=2, x= (1-y-z)/2=(1-2-1)/2=-1
总结上面过程,高斯消元法其实就是下面非常简单的过程
原线性方程组 ——> 高斯消元法 ——> 下三角或上三角形式的线性方程组 ——> 前向替换算法求解(对于上三角形式,采用后向替换算法)
下面是思路代码:
#include <iostream>#include <vector>
using namespace std;
// 定义矩阵类型,用于存储方程组的系数矩阵typedef vector<vector<double>> Matrix;
// 高斯消元函数,将方程组化为上三角矩阵bool gaussian_elimination(Matrix& A, vector<double>& b) { int n = A.size();
for (int i = 0; i < n; ++i) { // 寻找主元素 int pivot_row = i; for (int j = i + 1; j < n; ++j) { if (abs(A[j][i]) > abs(A[pivot_row][i])) { pivot_row = j; } }
// 交换当前行和主元素所在行 swap(A[i], A[pivot_row]); swap(b[i], b[pivot_row]);
// 如果主元素接近于零,则无法继续计算 if (abs(A[i][i]) < 1e-10) { return false; }
// 将当前行的主元素缩放为1 double pivot = A[i][i]; for (int j = i; j < n; ++j) { A[i][j] /= pivot; } b[i] /= pivot;
// 使用当前行的主元素将下面的行消元 for (int j = i + 1; j < n; ++j) { double factor = A[j][i]; for (int k = i; k < n; ++k) { A[j][k] -= factor * A[i][k]; } b[j] -= factor * b[i]; } }
return true;}
// 回代函数,解出方程组的解vector<double> back_substitution(const Matrix& A, const vector<double>& b) { int n = A.size(); vector<double> x(n);
for (int i = n - 1; i >= 0; --i) { x[i] = b[i]; for (int j = i + 1; j < n; ++j) { x[i] -= A[i][j] * x[j]; } }
return x;}
int main() { // 示例方程组的系数矩阵 A 和右侧常数向量 b Matrix A = {{2, 1, -1}, {-3, -1, 2}, {-2, 1, 2}}; vector<double> b = {8, -11, -3};
// 解线性方程组 if (gaussian_elimination(A, b)) { vector<double> solution = back_substitution(A, b); cout << "Solution:" << endl; for (int i = 0; i < solution.size(); ++i) { cout << "x[" << i << "] = " << solution[i] << endl; } } else { cout << "No unique solution exists." << endl; }
return 0;}求质数
试除法
如果我们想要知道小于等于n有多少个素数呢?
一个自然的想法是对于小于等于n每个数进行一次质数检验。这种暴力的做法显然不能达到最优复杂度。
//计算质数的代码(暴力根源)#include <iostream>using namespace std;int main(){ int i, j, count; cout << " 它的2到100间的质数有: \n"; for(i=2;i<100;i++) { count = 0; for(j=2;j<i;j++)//判断i是否为质数,若count==0则为质数 { if(i%j == 0) { count++; break; } } if(count==0) { cout<<i<<" "; } } cout << "\n";}在前面的基础上,加上了合数优化:
-
如果一个数是合数(不是素数),那么它可以被分解为两个或更多个正整数的乘积。
-
如果一个数
n是合数,那么它的最小因子(除了1以外)一定不会大于它的平方根sqrt(n)。
基于这两个观察,可以得出合数优化的原理:
- 在判断一个数是否为素数时,只需要检查从2到该数的平方根的整数范围内是否存在能整除该数的整数,而不必遍历整个范围直到该数本身。这是因为如果一个数
n是合数,那么它一定可以被表示为n = a * b,其中a和b是两个大于1的整数。如果a大于sqrt(n),那么b必然小于sqrt(n),因为a * b = n。因此,我们只需要检查从2到sqrt(n)的整数范围内是否存在能整除n的整数,如果存在,就可以确定n是合数。如果不存在,那么n就很可能是素数。
//加上合数优化//这里解决的是,判断这个数据是否为质数#include<iostream>using namespace std;
bool i_p(int x){ if(x<2) return false; //如果一个数是合数(不是素数),那么它的最小因数一定不会超过它的平方根 //这个属性可以用反陈述来证明。设 a 和 b 是 n 的两个因子,使得 a*b = n。如果两者都大于 √n,则 a.b > √n, * √n,这与表达式 “a * b = n” 相矛盾。(可以理解为 a 和 b 最大就 √n) for(int i = 2;i<=x/i;i++) if(x%i == 0) return false; return true;
}
int main(){ int n; cin>>n;
while(n--){ int x; cin>>x; if(i_p(x)) puts("Yes"); else puts("No"); } return 0;
}试除法求约数
前面利用试除法判断一个数据是否为质数,现在求n这个数据内部有多少约数。
#include<iostream>#include<algorithm>#include<vector>
using namespace std;
vector<int> get_divisors(int x){ vector<int> res; for(int i = 1;i<=x/i;i++) //整除流入 if(x%i == 0){ //如果i是质因数 - 塞入res数组中 res.push_back(i); //除数相等的情况 就只有i了嘛 if(i!=x/i) res.push_back(x/i); } //排个序 (可不可以用 set存储啊) sort(res.begin(),res.end()); return res;}
int main(){ int n; cin>>n;
while (n -- ){ int x; cin>>x; auto res = get_divisors(x); for( auto x:res) cout<<x<<" "; cout<<endl; } return 0;
}下面的代码用于计算一组整数的最小公倍数的约数个数:
#include<bits/stdc++.h>using namespace std;
typedef long long LL;const int N = 110, mod = 1e9 + 7;
int main(){ int n; cin >> n;
unordered_map<int, int> primes; // 使用哈希表存储质因数及其指数
while (n--) { int x; cin >> x;
// 分解质因数 for (int i = 2; i * i <= x; i++) { while (x % i == 0) { x /= i; primes[i]++; // 记录每个质因数的指数 } }
if (x > 1) primes[x]++; // 如果剩余的数大于1,说明它本身是一个质数,记录其指数 }
LL res = 1; for (auto p : primes) { res = res * (p.second + 1) % mod; }
cout << res << endl; return 0;}质数筛

埃拉托色尼筛的原理是这样的:
- 首先,把所有小于等于n的自然数都列出来,从2开始,把1排除掉。
- 然后,从2开始,把它的所有倍数都标记为合数,也就是不是素数的数。
- 接着,找到下一个没有被标记的数,它一定是素数,然后把它的所有倍数都标记为合数。重复这个过程,直到没有更多的没有被标记的数为止。
- 最后,所有没有被标记的数就是素数
#include<iostream>using namespace std;
const int N = 1e6+10;
int primes[N],cnt;bool st[N];
void get_primes(int n){ for(int i = 2;i<=n;i++){ if(st[i]) continue; // primes[cnt++] = i;的作用是把i这个素数存入primes数组中 // 并且把cnt加一,表示素数的个数增加了一个。 primes[cnt++] = i; // 这个循环的作用是把i的所有倍数都标记为合数,也就是非素数。 // 这样,当i增加时,就可以跳过已经被标记为合数的数字,只考虑没有被标记的数字,因为它们可能是素数。 for(int j = i+i;j<=n;j+=i) st[j] = true; }}
int main(){ int n; cin>>n; get_primes(n); cout<<cnt<<endl; return 0;
}线性筛法
线性筛法的主要思想是,对于每个数x,只考虑它的最小质因数。初始时,将每个合数(非素数)标记为其最小质因数。然后,从小到大遍历2到n的整数,如果某个数x还没有被标记为合数,那么它就是素数,并且将它的倍数标记为x。线性筛法的关键是避免多次标记。对于每个数x,它只会被其最小质因数标记一次,因此不会重复标记。这使得线性筛法的时间复杂度相对较低,比传统的埃拉托斯特尼筛法更高效,特别是在生成大量素数时。
以下是线性筛法的基本步骤:
- 初始化一个布尔数组(或标记数组)
is_prime,用于标记每个整数是否为素数。初始时,所有数都标记为素数。 - 初始化一个数组
primes,用于存储生成的素数。初始时,primes为空。 - 从2开始遍历到n的每个整数x:
- 如果
is_prime[x]为true,表示x是素数,将x添加到primes数组中。 - 对于x的每个质因数p(p从2开始,逐渐增加),将x * p标记为合数,并将最小质因数设置为p。
- 如果x被标记为合数后,跳出内层循环。
- 如果
- 当遍历完2到n的所有整数后,
primes数组中就包含了所有小于等于n的素数。
//线性筛法(埃拉托色尼筛优化版)#include <iostream>#include <algorithm>
using namespace std;
const int N= 1000010;
int primes[N], cnt;bool st[N];
void get_primes(int n){ for (int i = 2; i <= n; i ++ ) { //如果i没有被标记为合数,就把它加入到primes数组中,并且把cnt加一。cnt是用来记录素数的个数的变量。这样可以把所有的素数都存储起来,方便后面的使用。 if (!st[i]) primes[cnt ++ ] = i; for (int j = 0; primes[j] <= n / i; j ++ ) { //primes[j] * i这个数标记为合数 st[primes[j] * i] = true; //如果i能被primes[j]整除,就跳出循环,这样可以避免重复地标记一些合数。 if (i % primes[j] == 0) break; } }}
int main(){ int n; cin >> n;
get_primes(n);
cout << cnt << endl;
return 0;}求组合数
组合计数
在中学数学中,我们其实已经学会了组合数的公式了,基础的公式是:
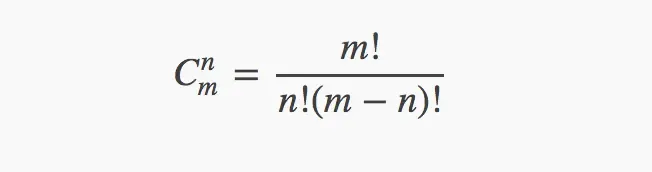
线性写法为:c(m,n) = m!/((m-n)!*n!)
但是,如果按照公式计算,时间复杂度非常高,下面是一个原始组合数模版代码:
#include <iostream>using namespace std;
// 计算阶乘unsigned long long factorial(int n) { if (n == 0 || n == 1) { return 1; } else { return n * factorial(n - 1); }}
// 计算组合数unsigned long long combination(int n, int k) { if (k < 0 || k > n) { return 0; } else { return factorial(n) / (factorial(k) * factorial(n - k)); }}
int main() { int n, k; cout << "请输入总数n:"; cin >> n; cout << "请输入要选择的元素数k:"; cin >> k;
unsigned long long result = combination(n, k);
cout << "组合数 C(" << n << ", " << k << ") = " << result << endl;
return 0;}这个代码使用的是递归的思想,来计算这个组合数,当然在这个模版的基础上,我们也可以将之优化.
采用阶乘计算稍大数组合数是不合适的,而且效率不高,但是可以先对公式进行转换然后再进行计算: 1.对公式两边取自然对数
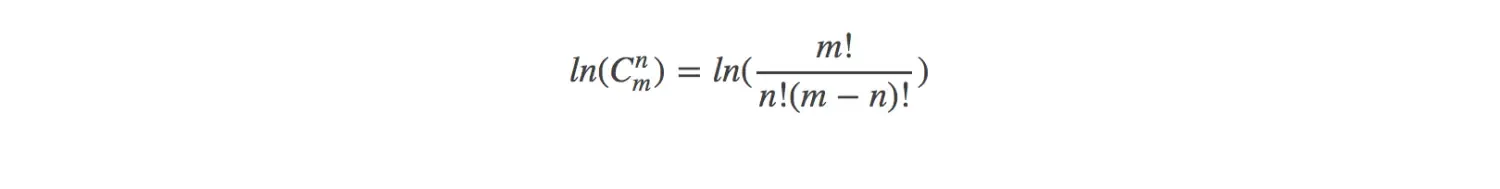
2.根据对数性质进行转换
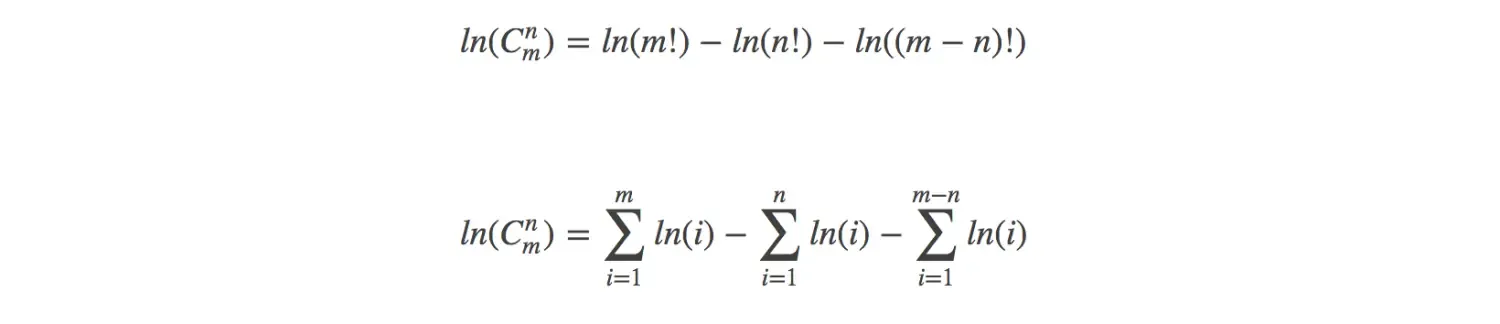
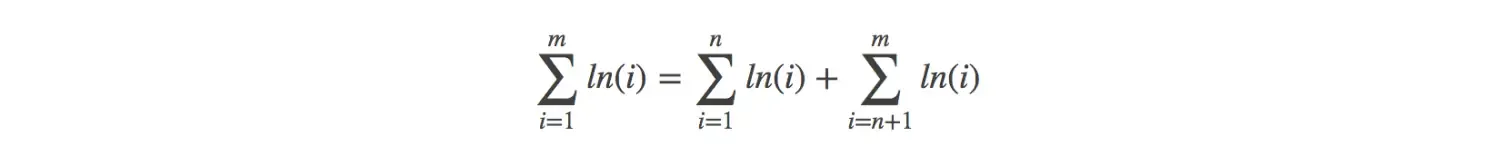
-
消除相同项
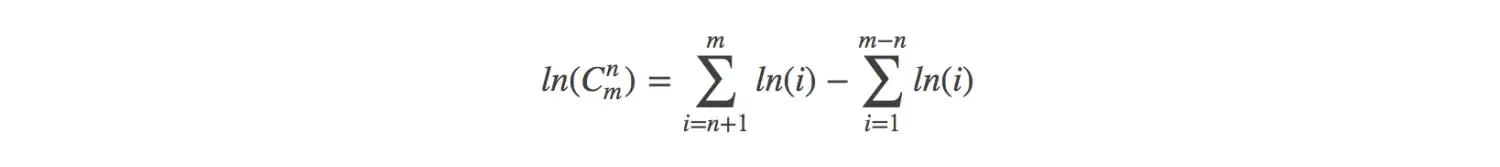
-
到这就已经将阶乘转换成对数连加,极大的降低了运算的复杂度。另外,依据组合数性质:
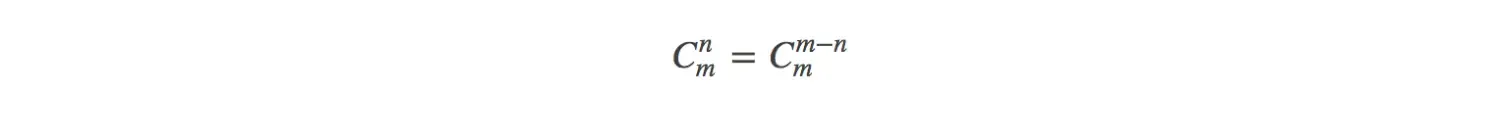
当 n > m/2时,n 相对于 m - n是一个较大的数,此时可以取 n = m - n进行计算。
3.进行计算 以第2步得到的公式计算出
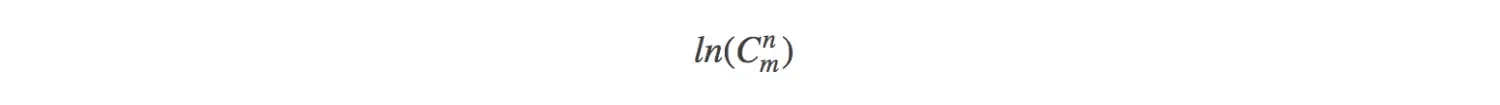
的值,然后再取反对数就可以得到组合数结果了。
用这种方法计算组合数,如果只计算ln(C(m,n))的话,n可以取到整型数据的极限值65535,ln(C(65535,32767)) = 45419.6
而计算时间可以达到毫秒级。当然,如果要取反对数得到最终的组合数的话,m的取值就不能达到这么大了,但是这种算法仍然可以保证m取到1000以上。
#include <iostream>#include <cmath>
// 计算组合数的自然对数double logCombination(int n, int k) { if (k < 0 || k > n) { return 0.0; }
double result = 0.0;
for (int i = 1; i <= k; i++) { result += log(static_cast<double>(n - i + 1)) - log(static_cast<double>(i)); }
return result;}
int main() { int n, k; std::cout << "请输入总数n:"; std::cin >> n; std::cout << "请输入要选择的元素数k:"; std::cin >> k;
double result = exp(logCombination(n, k)); // 恢复为普通数值
std::cout << "组合数 C(" << n << ", " << k << ") = " << result << std::endl;
return 0;}卢卡斯定理
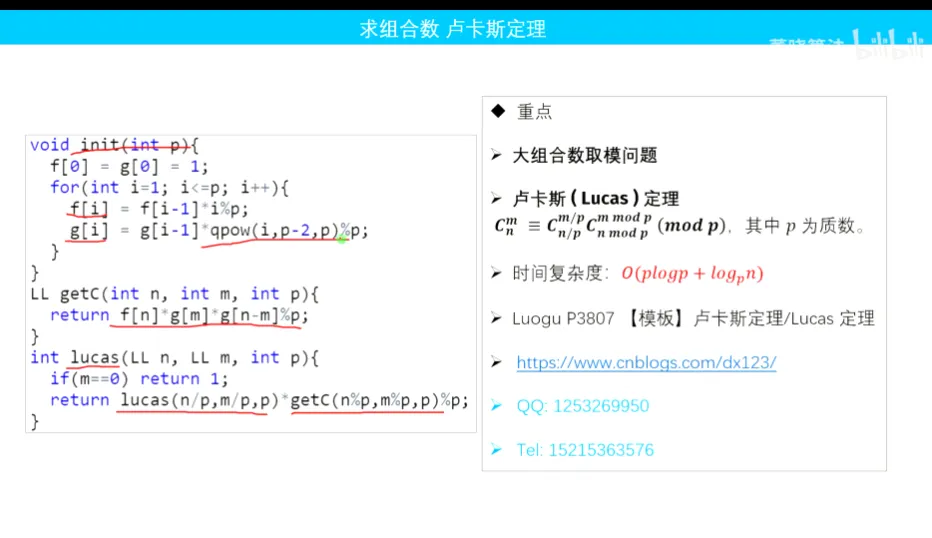
卢卡斯定理的主要内容是描述如何将组合数C(n, k) 模素数p 分解为更小的组合数的乘积,然后再模p运算。具体来说,定理陈述如下:
-
对于给定的正整数n、k 和素数p(p 必须大于n),可以将组合数C(n, k) 模p 分解为以下形式的乘积:
C(n, k) ≡ C(n mod p, k mod p) * C(n/p, k/p) (mod p) -
其中,
C(n mod p, k mod p)表示将n 和k 分别模p 后的余数所对应的组合数,C(n/p, k/p)表示将n 和k 分别除以p 后的商所对应的组合数。
卢卡斯定理在计算组合数模素数时非常有用,因为它可以将大的组合数分解成小的组合数,并通过模运算得到结果,从而避免大整数计算。

#include <iostream>using namespace std;int f[20][20];//定义二维数组,用来中间存储计算结果int cmn(int m,int n){ int i,j; for(i=0;i<=m;++i) //循环m步,从0开始 for(j=0;j<=n;++j) //循环n步,也是从0开始 if(j==0||i==j) //当i等于0或者i等于j时,直接赋值为1 f[i][j]=1; else f[i][j]=f[i-1][j-1]+f[i-1][j];//其他的都是在上一步的计算结果上加+1,依次类推 return f[m][n]; //返回结果}int main(){ int m,n; cout<<"请输入任意m.n来得到组合数:"; cin>>m>>n; int result=cmn(m,n); cout<<m<<"C"<<n<<"="<<result<<endl; //输出结果 return 0;}